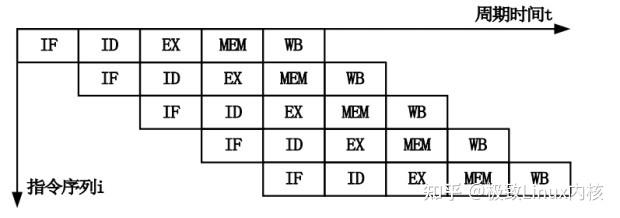
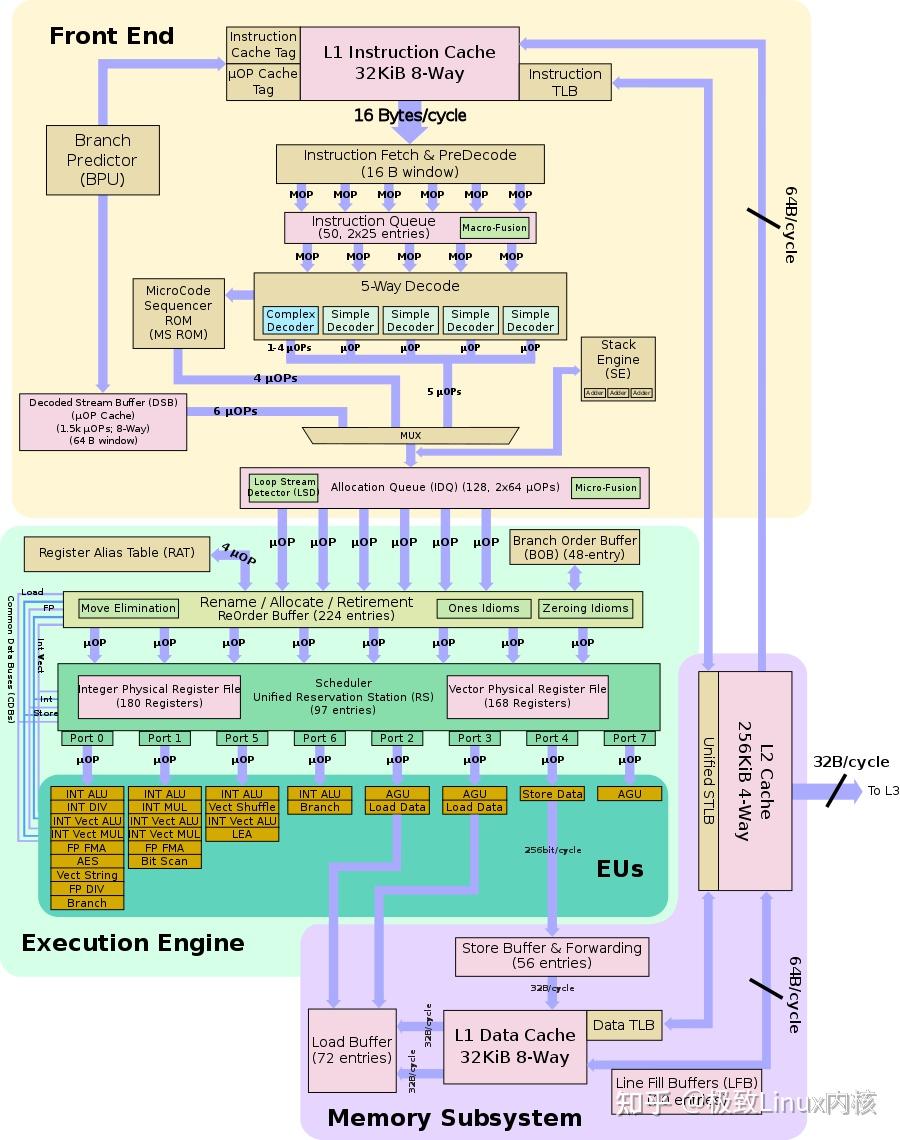
作为最后一个阶段,结果写回(Writeback,WB)阶段把执行指令阶段的运行结果数据“写回”到某种存储形式:结果数据经常被写到 CPU 的内部寄存器中,以便被后续的指令快速地存取;在有些情况下, 结果数据也可被写入相对较慢、但较廉价且容量较大的主存。许多指令还会改变程序状态字寄存器中标志位 的状态,这些标志位标识着不同的操作结果,可被用来影响程序的动作。
在指令执行完毕、结果数据写回之后,若无意外事件(如结果溢出等)发生,计算机就接着从程序计数器 PC 中取得下一条指令地址,开始新一轮的循环,下一个指令周期将顺序取出下一条指令。许多新型 CPU 可以同时取出、译码和执行多条指令,体现并行处理的特性。
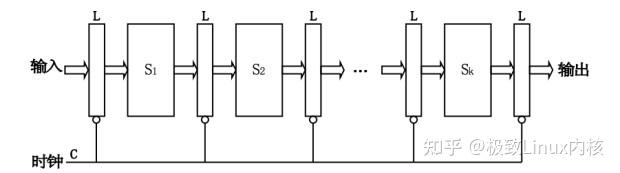
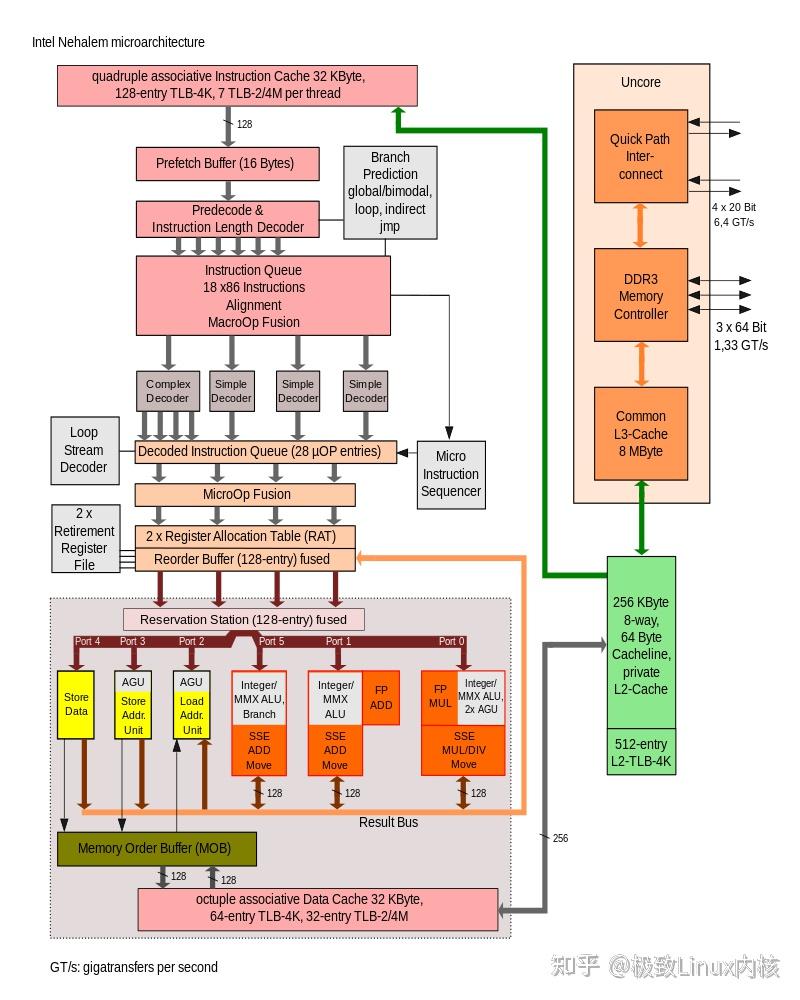
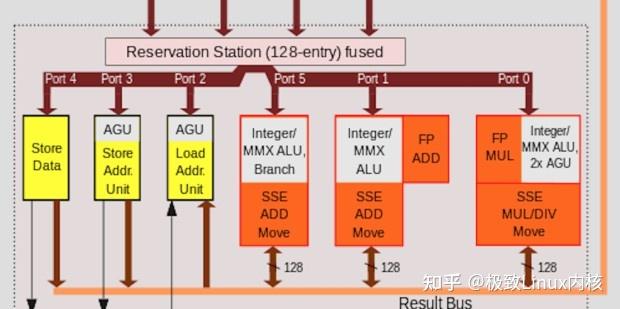
二、CPU指令流水线
乱序执行(Out-of-order Execution)是以乱序方式执行指令,即 CPU 允许将多条指令不按程序规定的顺序而分开发送给各相应电路单元进行处理。这样,根据各个电路单元的状态和各指令能否提前执行的具体情况分析,将能够提前执行的指令立即发送给相应电路单元予以执行,在这期间不按规定顺序执行指令;然后由重新排列单元将各执行单元结果按指令顺序重新排列。乱序执行的目的,就是为了使 CPU 内部电路满负荷运转,并相应提高 CPU 运行程序的速度。
实现乱序执行的关键在于取消传统的“取指”和“执行”两个阶段之间指令需要线性排列的限制,而使用一个指令缓冲池来开辟一个较长的指令窗口,允许执行单元在一个较大的范围内调遣和执行已译码的程序指令流。
3.分支预测
分支预测(Branch Prediction)是对程序的流程进行预测,然后读取其中一个分支的指令。采用分支预测的主要目的是为了提高 CPU的运算速度。 分支预测的方法有静态预测和动态预测两类:静态预测方法比较简单,如预测永远不转移、预测永远转移、预测后向转移等等,它并不根据执行时的条件和历史信息来进行预测,因此预测的准确性不可能很高;动态预测方法则根据同一条转移指令过去的转移情况来预测未来的转移情况。 由于程序中的条件分支是根据程序指令在流水线处理后的结果来执行的,所以当 CPU 等待指令结果时, 流水线的前级电路也处于等待分支指令的空闲状态,这样必然出现时钟周期的浪费。如果 CPU 能在前条指令结果出来之前就预测到分支是否转移,那么就可以提前执行相应的指令,这样就避免了流水线的空闲等待,也就相应提高了 CPU 的运算速度。但另一方面,一旦前条指令结果出来后证明分支预测是错误的,那么就必须将已经装入流水线执行的指令和结果全部清除,然后再装入正确的指令重新处理,这样就比不进行分支预测而是等待结果再执行新指令还要慢了。
因此,分支预测的错误并不会导致结果的错误,而只是导致流水线的停顿,如果能够保持较高的预测 准确率,分支预测就能提高流水线的性能。
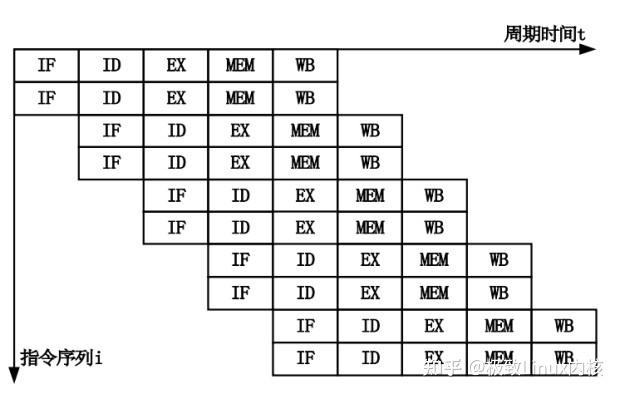
五、实例分析
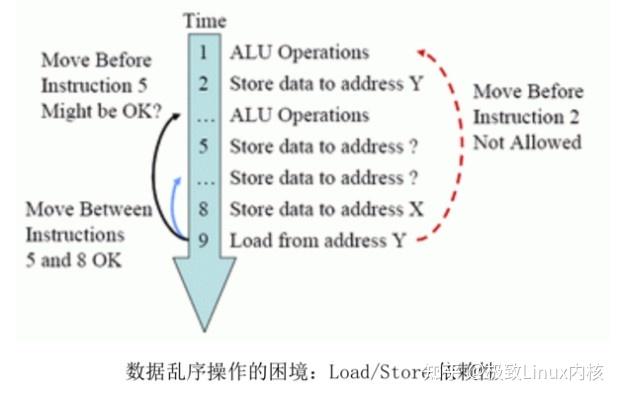
如上图所示,第一条 ALU 指令的运算结果要 Store 在地址 Y(第二条指令),而第九条 指令是从地址 Y Load 数据,显然在第二条指令执行完毕之前,无法移动第九条指令,否则将会产生错误的结果。同样,如果CPU也不知道第五条指令会使用什么地址,所以它也无法确定是否可以把第九条指令移动到第五条指令附近。
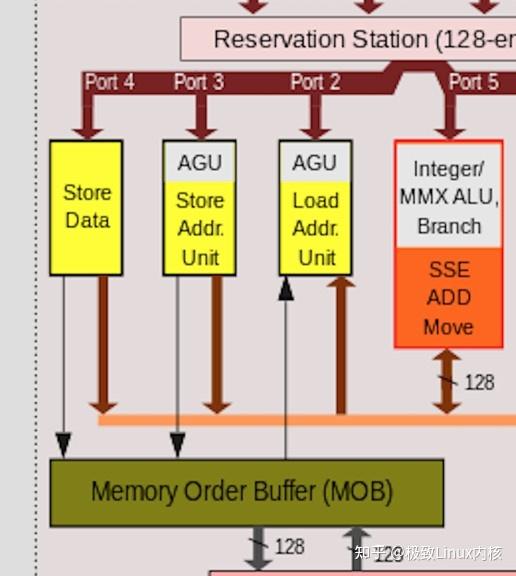
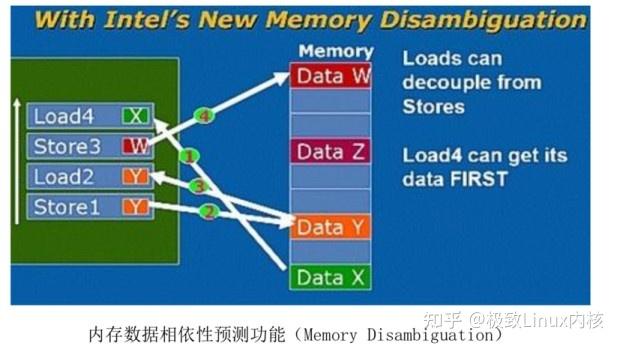
内存数据相依性预测功能(Memory Disambiguation)可以预测哪些指令是具有依赖性的或者使用相关的地址(地址混淆,Alias),从而决定哪些 Load/Store 指令是可以提前的, 哪些是不可以提前的。可以提前的指令在其后继指令需要数据之前就开始执行、读取数据到ROB当中,这样后继指令就可以直接从中使用数据,从而避免访问了无法提前 Load/Store 时访问 L1 缓存带来的延迟(3~4 个时钟周期)。
不过,为了要判断一个 Load 指令所操作的地址没有问题,缓存系统需要检查处于 in-flight 状态(处理器流水线中所有未执行的指令)的 Store 操作,这是一个颇耗费资源的过程。在 NetBurst 微架构中,通过把一条 Store 指令分解为两个 uops——一个用于计算地址、一个用于真正的存储数据,这种方式可以提前预知 Store 指令所操作的地址,初步的解决了数据相依性问题。在 NetBurst 微架构中,Load/Store 乱序操作的算法遵循以下几条 原则:
如果一个对于未知地址进行操作的 Store 指令处于 in-flight 状态,那么所有的 Load 指令都要被延迟
在操作相同地址的 Store 指令之前 Load 指令不能继续执行
一个 Store 指令不能移动到另外一个 Store 指令之前(指的是在RS中不能先挑选执行后面的一条store指令,注意这只是说某一种架构不允许重排store,其实还是有很多架构如Alpha等是松散内存模型,允许不相关的store重排序的,这一块就牵扯到memory models相关知识了,建议参考这里)



 发表于 2023-7-24 10:38:47
发表于 2023-7-24 10:38:47